
What is a Data Warehouse ?
- From a purely technical, low-level, standpoint, a Data Warehouse is a database like any other. It has tables with relations between them, indexes, views, sequences etc.
- Data Warehouses are typically large. They are used for storing all the data the organization needs in order to make data-driven decisions. It’s a “warehouse” because you collect all of your relevant data, from all of your databases(and sometimes external sources) and store it in the warehouse. Modern data warehouses are built as a collection of data marts developed one after the other in short, agile sprints.
- All data from all sources is collected into one place which ideally operates using one technology. A company can have several operational databases using different technologies(Hadoop, Oracle, MongoDB, SQL-Server, Excel files etc.). In the Data Warehouse all the information sits in one place, and one technology, allowing users to cross information between systems. For example, a system used by the compliance team uses a MongoDB database, while most other data sits in MS-SQL. The Data Warehouse is a place to collect both sources and be able to analyze data from both sources in one place.
- Some of the data comes from external sources: business partners, government services, marketing platforms, social media, cloud services etc.
- From a modelling standpoint, a Data Warehouse is very different from a traditional operational database. While there are still tables with data, the schema we use is optimized for reporting. The most common Data Warehouse schema design is Ralph Kimball’s dimensional model – a schema shaped like a star (called a “star-schema”). I won’t go into much details here, but it’s a model that is optimized for analyzing large volumes of information. In the center of the star schema, there’s a fact table(or tables), which store the events that have happened(customers joining, sales transactions, shipment events, phone calls etc.) and around the fact table, there are dimension tables used to describe these events(what,who, when,why,where, how etc.). Here is an example of star schema used by a customer services database:
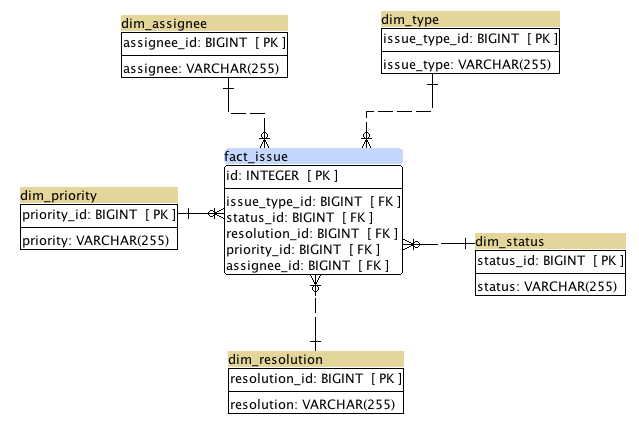
- The data is loaded from the different sources using ETL processes. ETL stands for Extract (data from sources), Transform (the data into a star schema) and Load (into the Data Warehouse). The ETL code is the one place where you keep the logic – the ONE VERSION OF THE TRUTH, which is the most crucial aspect of data systems. Example : if we decide to count new users as all users who’ve deposited money, and they are from a specific list of eligible countries, this is where this rule sits(deposited money, from a specific list of countries). This is the only place where this logic is calculated, and all reports just read this “new users” measure and expect the number to be a fact.
- Assuming the Data Warehouse is built and maintained as part of the IT organization, every technical change in source databases can be immediately reflected in the data warehouse. In fact, every new project/feature/change potentially has data warehouse implications.
What is a BI system ?
- Short and sweet : a convenient place to view information that helps make decisions.
- Typically a set of pre-built reports + a product that allows creation of ad-hoc reports.
- There are allot of BI products that can be bought and used to create reports. These products connect to the data warehouse (but can also connect to any source of data). Some organizations choose to create their own reporting systems. Excel can be used as well, at earlier stages.
- Current market leaders: Microsoft’s Power BI, Tableau, Qlik.
- New BI products, mainly Power BI, are marketed as “self-serve”, meaning end users can easily create their own reports. While it’s true that they are easy to learn and use, the absence of an underlying data warehouse or data marts can be dangerous. I talked about it here.
What happens without a BI + DW system?
- Users need information and they find ways to get it : extract data from operational systems(CRM,sales etc.), keep their own information in excel files, ask for favours from developers or database administrators..
- Users who have access pull data from operational databases and cause performance issues. An operational database is not built for reporting. It doesn’t have the right parameters configured and doesn’t have a star schema in place. The queries often require joining many tables together and are complicated to write. Locking can cause issues as well.
- Reports created by different people use different definitions and different namings. Two employees could define “Premium Users” and mean two different things. Tens or even hundreds versions of the truth.
- Data is consumed from a “What do I need to know now” point of view. If a user is focused on understanding how much did a Russian sales team bring in last month, that’s what they will look for. For every information problem, somehow a report is created. There’s no place for a data analyst/scientist to explore the data free-style and look for insights.
- Reports that users create for themselves, break very often because IT/dev are not involved. Every technical change to the database can break a report logic.
- The logic is kept in the reports, rather than in one place – every change needs to be done in tens or hundreds of places, by many different users.
OK, so how do I get one?
As mentioned above, the modern approach is to built small data marts in a quick and agile fashion. These data marts comprise the data warehouse eventually. Think about where you want to start, what would be the 5 most important KPIs of your organisation? net customer growth / best selling products/ customer service satisfaction etc. My approach is to usually build a first, small data mart concentrating around one question, and start creating reports over Power BI. I’m happy to help you get started.
1 Comment. Leave new
Very well explained, thank you!